This week we looked at “Autoscaling Tiered Cloud Storage in Anna.” This is the second Anna paper. The first one introduces Anna Key-Value store, and the second paper talks about various “cloud-native” improvements. The presentation by Michael Whittaker is available here:
Short Summary
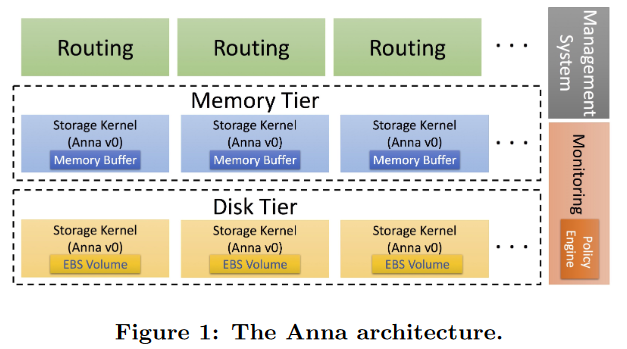
Anna is an eventual-consistent key-value data store, where each value is a lattice. Anna can tweak some consistency guarantees by changing the type of lattice stored in the value. For example, it can be a Last Write Wins (LWW) system that merges operations based on the definition of the last writer (i.e. a timestamp), or it can use some CRDT lattice to preserve all updates/operations. The weak consistency of Anna means that it is relatively easy to add and remove nodes to scale the systems. The Autoscaling part takes advantage of that and dynamically adjusts the number of replicas responsible for each key to match the workload. Moreover, Autoscaled Anna has multiple usage tiers for keys based on the usage frequency. The paper discusses “hot” and “cold” keys, but more tiers are possible. Such tiering allows using heterogeneous hardware to better balance the cost and performance of Anna, as “cold” keys may run on cheaper hardware backed by SSDs, while “hot” keys may be store in RAM on more expensive VMs. Anna has rules for data transitioning between tiers and for controlling the degree of replication. For example, there is a minimum replication factor for durability, and there are usage thresholds for promoting and demoting keys to/from hot/cold tiers.
Discussion
We have spent quite some time talking about this paper, as there is a lot of information to digest. Below are a few of the bigger discussion points
1) Apache Cassandra comparison. This came up a few times as lacking, as the system is somewhat similar to Cassandra, at least when you consider the LWW lattice. There are many differences too, especially in the context of autoscaling. Cassandra uses a statically configured replication factor and lacks any autoscaling. Cassandra’s DHT model is pretty rigid and resists scaling – adding nodes require considerable ring rebalancing. Also, only one node can be added/removed from the ring at once to avoid membership and ring partitioning issues. Anna has no such problem and can adjust quicker and more dynamic. Additionally, for all the fairness, the original Anna paper compares against Cassandra.
2) Breaking Anna. Part of the discussion was around breaking the autoscaling and putting Anna in a bad/less-performant state. One example would be using a workload that changes at about the same rate as Anna can adjust. For example, if we hit some keys above the threshold to promote from the “cold” tier to “hot”, we can cause a lot of data movement as these keys potentially migrate or added to the memory-tier hardware. At the same time, we can reduce the usage, causing the systems to demote these keys, and experience associated overheads. This is like putting a workload in resonance with Anna’s elastic abilities, and it reminds me of a famous Tacoma Narrows bridge collapse
3) Possible consistency guarantees. One of the benefits of Anna is that some guarantees can be tweaked based on the lattice used for the value. Part of the discussion focused on how much consistency we can get purely out of these lattices, and how much may necessitate more drastic architectural changes. It is pretty straightforward to understand that Anna won’t ever provide strong consistency, but what about some other guarantees? For example, the original Anna paper claims the ability to have causal consistency, although it uses more complicated lattices, and keeps vector clocks for maintaining causality, not only making the system more complicated but also potentially harming the performance (something noted by the authors themselves).
4) Comparison fairness. Some points were mentioned about the evaluation fairness. It appears that some systems compared against are significantly more capable and/or may provide better guarantees(DynamoDB, Redis). It is worth noting, however, that there are not that many, if any, direct competitors, so these comparisons are still very valuable.
5) Cloud-Native. This appears as one the “most” cloud-native database papers that talks about some practical aspects of designing and running a cloud-native database. One aspect of this “cloud-nativeness” is the focus on elasticity and scalability happening automatically. Another one is the cost-performance consideration in how the system scales with regard to workload changes. We noted some other much older papers that fit our definition of “cloud-native” papers. One example was Yahoo’s PNUTS paper that describes a global system with some capability to adjust to workloads and selective replication.
6) Scheduling/resource allocation. One of the challenging aspects of Anna with autoscaling is figuring out the best key “packing” or binning” given multiple tiers and pricing constraints. This is similar to a Knapsack problem and bin packing problem, and both are NP-complete. So this resource management/scheduling will become a big problem at the production scale when we may have thousands of machines. At the same time, task packing problems at the datacenter level are well studied, for example in Google’s Borg cluster management system or its derivative Kubernetes
Our reading groups takes place over Zoom every Wednesday at 3:30pm EST. We have a slack group where we post papers, hold discussions and most importantly manage Zoom invites to the papers. Please join the slack group to get involved!