Recently I was reading the “Building Consistent Transaction with Inconsistent Replication” paper. In this paper authors use inconsistently replicated state machine, but yet they are capable of creating a consistent transaction system. So what is Inconsistent Replication (IR)?
In the previous posts I summarized Raft and EPaxos. These two algorithms are used to achieve consensus in the distributed system, so for example when we deal with replicated state machines, these algorithms allow each replica to be an exact, consistent copy of each other. So, it is logical to assume that Inconsistent Replication will not produce the same replicas all the time, so our state machines can end up in different states. Why would we want to have a replicated state machine with various copies potentially being in different states? According to the authors of the paper it is faster than consistent replication, yet can still be used in some applications, such as transaction commit. I think the usage of IR will not be as straightforward as using consistent replications, since users of IR must also design their applications in such a way that tolerates the inconsistent state of the nodes.
IR does not guarantee the order in which each command is executed by replicas, thus replicas can reach different states unless the operations are independent of each other. The figure below illustrates hot this can happen.
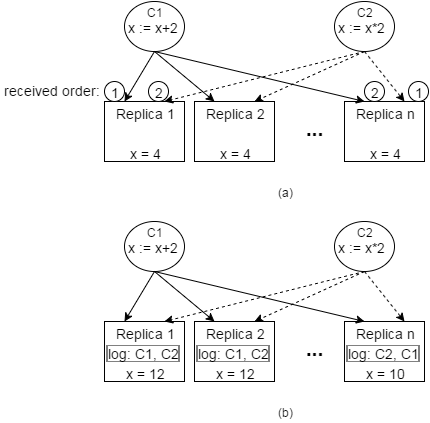
Figure 1. Replicas in inconsistent state. (a) Two requests C1 and C2 are being sent to replicas at the same, but the requests reach replicas in different orders. (b) Requests are logged and executed in the order they have been received leading to an inconsistent state.
Since replicas can be in different states, IR cannot guarantee that recovering from failures can preserve the value or the states of each recovered operation. Because of this, IR has two types of guarantees it can provide upon recovering from a failure. If a client does not need to have an ability to recover the value of each operation, it can use IR in an inconsistent operation mode that only guarantees the recovery of only the fact that an operation occurred for up to f failures in a system of 2f+1 replicas. Inconsistent operation mode does not allow to recover the value of the operation. In consensus operation mode, IR can preserve both the command and a result of such command for up to f failures. In this mode, the result of an operation is the result a majority of replicas report for such operation, if such majority exist. Consensus operation may fail if not enough replicas report the same result for the operation, in which case IR protocol retries. Consensus operations also need to have floor(3/2f)+1 replicas agree to be finalized. IR protocol will also retry the operation until it finalizes. It seems like only finalized consensus operation can be recovered with the results of the operation, and not all consensus operation can be finalized since they can timeout after getting the majority but before reaching the consensus on floor(3/2f)+1 replicas.
This notion of retrying the operations until they eventually succeed makes me question whether it is a good solution especially under various kinds of loads. If the system deals with mostly independent requests it may not be difficult to reach consensus in consensus operation mode, but if there are lot of contention between requests, the system may just be stuck retrying all the operations without doing much of a useful work.
I am not going mention IR recovery mechanism described in the paper, but it is worth noting that during the recovery the entire system blocks and stops responding to new requests. The process is initialized by a recovering replica communicating to all other nodes, and once each node learns that some other replica is recovering from a failure it stops processing the requests until the protocol is finished and normal operation can resume.